JDBC LOB Prefetching
20 Dec 2018In Oracle JDBC version 11.2 LOB prefetching was introduced. The whole point of LOB prefetching is to reduce the number of roundtrips needed to get the LOB data.
The goal of this post is to show how LOB prefetching works and point out which variables influence the optimal prefetch value.
Basics of LOB access
With JDBC driver versions older than 11.2 the behaviour when fetching LOB data is as follows: The client fetches the amount of rows, depending on the set fetch size. If the rows include a LOB column, the client is provided with a LOB locator, which is basically a pointer to the LOB in the database. There is no actual LOB data sent to the client at this point. At the point where the LOB is accessed, e.g. by calling ResultSet.getClob, the client requests the LOB metadata from the database (like LOB length and chunk size). Then in a second step, the LOB data is requested from the database.
So, for every row 2 additional roundtrips are necessary to get the LOB data.
Since JDBC version 11.2 LOB prefetching is available, which can minimize the number of roundtrips. It can be set on the DataSource, Connection, Statement or even on column level by using one of the overloaded methods OracleStatement.defineColumnType. Check the documentation for more information.
LOB Prefetching
In JDBC version 11.2 the default value for LOB prefetching is -1 which disables LOB prefetching. Since 12.1 the default is 4000.
Metadata only
By setting LOB prefetching to 0, you enable metadata prefetching. For every LOB column, the metadata is already fetched with the rest of the row data. This avoids one extra roundtrip for each row when accessing the LOB, as described earlier.
LOB prefetching
Any value higher than 0, sets the amount of LOB data to be prefetched for each LOB. For CLOB data it defines how many characters, for BLOB data how many bytes that are prefetched. So for each LOB smaller than the set prefetch size, no additional round trip to the database is necessary.
Performance
As already mentioned, the whole point of LOB prefetching is to reduce the number of round trips to the database to get the LOB data. To measure the runtime of a simple query in different scenarios, I created a small benchmark where I always fetch the same data, but the following parameters are varying:
- Fetch size
- LOB prefetch size
- Network latency
Benchmark
All tests are done with Oracle JDBC 18.3 and Oracle Database 18.3. I’m not aware of any changes to how LOB prefetch work since version 11.2, but memory management has changed in the 12c driver, so it’s probably worth to execute the benchmark on your own if you use driver version 11.2.
First, we create a table with some LOB data
create table lobtest (id number(10), data clob);
insert into lobtest
select rownum, lpad('*', 4000, '*')
from dual
connect by rownum <= 1000;
commit;The benchmark itself is done with JMH. The test class can be seen here, but here’s a wrap-up what’s going on there.
For all combinations of benchmark parameters, the following steps are performed:
- Fetch 1000 rows in total.
- For every row, access all the data stored in the LOB column.
The parameters are as follows:
- LOB size: 4000 bytes.
- Total rows: 1000.
- Fetch size: 10, 100, 1000.
- LOB Prefetch: -1 (disabled), 0 (metadata), 2000 (half of the LOB), 4000 (whole LOB).
- Network latency: ~0.5ms, ~1.5ms. See this blog post on how to simulate network latency on Linux.
Results
Roundtrips
Let’s first have a look at the number of roundtrips needed. The chart simply shows how many times the database waited for SQL*Net message from client.
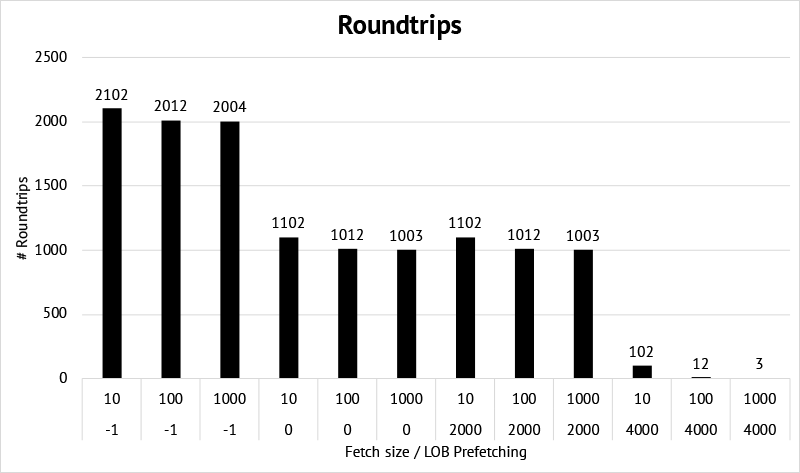
We see that
- The number of roundtrips is cut in half by using metadata prefetching.
- Prefetching just part of the LOB data, results in the same number of roundtrips as when we just prefetch the metadata. This is because in this benchmark the rest of the LOB is always fetched later on.
- By prefetching all the LOB data, the number of roundtrips is greatly reduced and mainly driven by the row fetch size.
Runtime
We saw the impact the different scenarios have on the number of roundtrips. The following chart shows the average runtime out of 10 runs for the various scenarios. The benchmark was performed with 2 different average network latencies (~0.5ms and ~1.5ms).
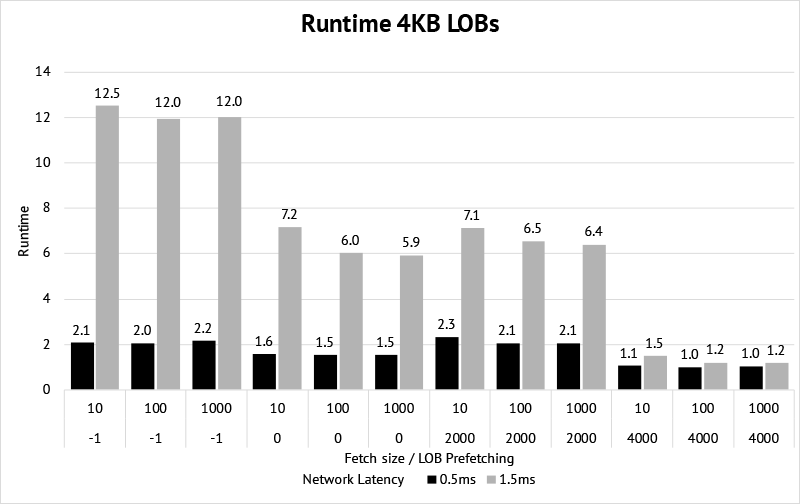 Note that the runtime was obfuscated and does not correspond to a real unit of time. The lowest runtime is set to 1, and the others are aligned accordingly.
Note that the runtime was obfuscated and does not correspond to a real unit of time. The lowest runtime is set to 1, and the others are aligned accordingly.
We see that
- The higher the latency, the bigger the impact of reducing the roundtrips by prefetching the LOBs.
- Prefetching only a part of the LOB, and access the rest later is slower than only prefetching the LOB metadata. I tested it also by fetching BLOB instead of CLOB data and access it with
ResultSet.getBytes. I suspect that’s because of some implementation detail in the JDBC driver and something that could change in the future.
Benchmark with 10MB LOBs
To get a feeling for what impact the size of the LOB has, I did a second benchmark with the following parameters:
- LOB size: 10 MB.
- Total Rows: 100.
- Fetch size: 10, 100.
- LOB Prefetch: -1 (disabled), 0 (metadata), 8000 (part of the LOB), 10485760 (whole LOB).
- Network latency: ~0.5ms.
Here’s the result:
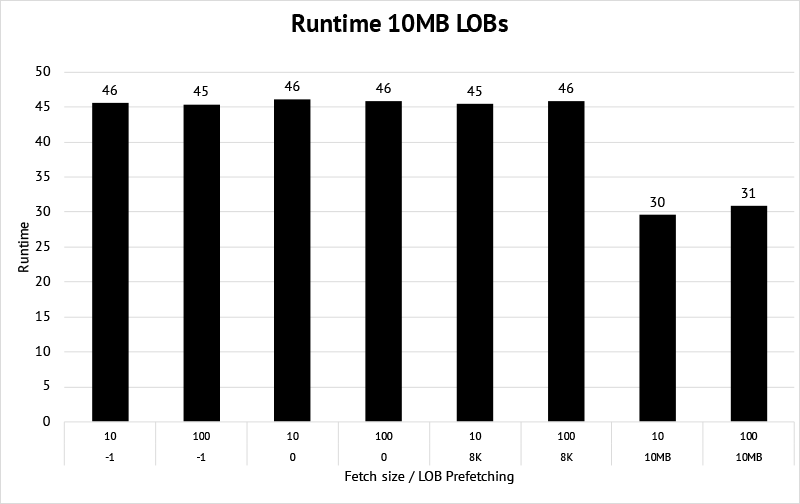 Note that the runtime was obfuscated and does not correspond to a real unit of time.
Note that the runtime was obfuscated and does not correspond to a real unit of time.
We see that
- Metadata prefetching or prefetching just part of the LOB data, does not show any runtime improvements in this case.
- Even though the improvement of fetching the whole LOB is not as big as with 4K LOB size, it’s still ~65% faster.
- Bigger LOBs (and same network latency) will further diminish the relative performance improvement.
Memory Consumption
I didn’t do any measurements on client-side memory consumption but you should be aware that row fetch size and lob prefetch size affect memory consumption.
If you for example, set LOB prefetch size to 4000 and row fetch size to 1000, the driver needs at least 10 times more memory than setting the fetch size to 100.
Conclusion
- With high network latency and small LOBs, the benefit of LOB prefetching will be most noticeable.
- The larger the LOBs get or the lower the network latency is, the less overall time is spent for the roundtrips and the benefit will be less significant.
- Setting the optimal value for LOB prefetching depends on your LOB size (or to be more precise, the amount of LOB data that is accessed), the fraction of LOBs that are really accessed (e.g. only every 10th LOB in your result set is accessed), network latency, and last but not least on your memory constraints.
- As many factors come into play when setting the optimal value, you have to test it under real conditions in your environment.